
Os conceitos básicos de arquitetura que eu queria ter conhecido quando comecei a carreira de desenvolvedor web
Jonathan Fulton, Nov 7, 2017 · leitura de 11 minutos
O texto a seguir foi traduzido do original por César Rodriguez. Original disponível em https://engineering.videoblocks.com/web-architecture-101-a3224e126947 (consulta em 27/09/2019).
Não estranhe se alguma parte da página ainda estiver em inglês (certamente é a que está sendo trabalhada no momento), ou se os links forem para páginas em inglês (se forem os artigos centrais, serão traduzidos no futuro).
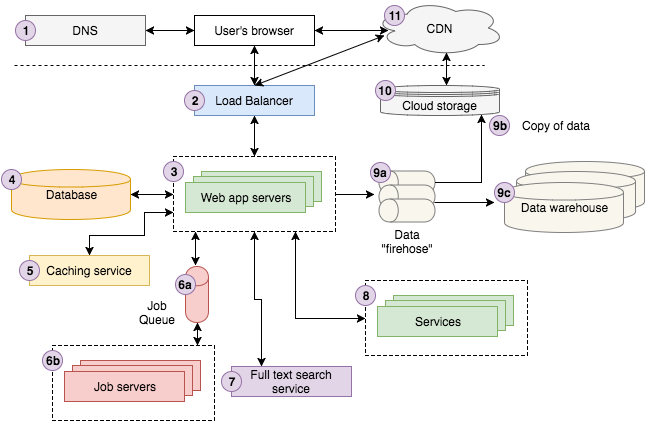
O diagrama acima é uma representação razoável de nossa arquitetura na Storyblocks. Se você não for um desenvolvedor web experiente, provavelmente achará muito complicada. O resumo dos próximos parágrafos tem a intenção de tornar o diagrama mais palatável, para que nós possamos aprofundar em cada um dos componentes.
Um usuário faz uma pesquisa no Google: “Nevoeiro Forte Bonito e Raios de Sol na Floresta” (no original, “Strong Beautiful Fog And Sunbeams In The Forest”). O primeiro resultado calha de ser do Storyblocks, o maior site de fotos e imagens vetoriais. O usuário clica no resultado da pesquisa, que redireciona o navegador para a página de detalhes da imagem. Por baixo dos panos, o navegador do usuário envia uma requisição para um servidor DNS, para descobrir como contatar o Storyblocks, e então envia a requisição da página para o site.
A requisição chega no nosso balanceador de carga, que escolhe aleatoriamente um dos mais ou menos 10 servidores que nós mantemos rodando simultaneamente no site para processar a requisição. O servidor web procura algumas informações sobre a imagem em nosso serviço de cache, e busca os outros dados no nosso banco de dados. Nós percebemos que o perfil de cor da imagem ainda não foi computado, portanto enviamos um trabalho de “perfil de cor” para a fila, que nossos servidores de serviços processarão de forma assíncrona, atualizando a base de dados com os resultados adequados.
Em seguida, nós tentamos encontrar fotos similares enviando uma requisição para nosso serviço de busca por text, usando o título da foto como parâmetro de busca. Como o usuário está logado como membro do Storyblocks, nós buscamos suas informações de conta do nosso serviço de contas de usuário. Por fim, nós disparamos um evento de visualização de página para nossa data firehose (em português, “mangueira de incêndio de dados”) para ser gravado no nosso sistema de armazenamento em nuvem e, eventualmente, carregado em nosso depósito de dados, o qual é utilizado por analistas para ajudar a responder perguntas sobre nossos negócios.
Neste momento, o servidor renderiza a página como HTML e envia de volta para o navegador do usuário — passando por nosso balanceador de carga. A página tem conteúdo Javascript e CSS, que estão armazenados em nosso sistema de armazenamento na nuvem, o qual está conectado a nosso CDN. Por isso, o navegador web do usuário contata o CDN para pegar esse conteúdo. Por último, o navegador renderiza a página na tela do usuário.
A seguir, vamos passar por cada componente, dando um “curso de introdução” a cada componente, que deve te dar um bom modelo mental para pensar sobre arquitetura web, enquanto prosseguimos. Ao final, apresentarei uma série de artigos com recomendações de implementação específicas, baseadas no que eu aprendi trabalhando no Storyblocks.
1. DNS
DNS significa “Sistema de Nome de Domínio ” (em inglês, Domain Name System). É uma das tecnologias fundamentais que tornam a internet possível. Em termos simples, o DNS permite buscar pares de chave/valor, usando nomes de domínio (e.g., google.com) para retornar um endereço IP (e.g., 85.129.83.120) — o qual é necessário para seu computador direcionar uma requisição ao servidor correto. Fazendo uma analogia com telefones, a diferença entre um nome de domínio e um endereço IP é como a diferença entre “ligar para Fulano” e “ligar para (71) 6233-3454”. Assim como antigamente você precisava de uma lista telefônica para procurar o telefone de Fulano, você precisa do DNS para pesquisar o endereço IP de um domínio. Portanto, você pode pensar no DNS como a lista telefônica da internet.
Nós poderíamos entrar em muito mais detalhes, mas vamos pular, pois não são essenciais para uma introdução.
2. Balanceador de Carga
Antes de analisar em detalhes o balanceamento de carga, nós precisamos dar um passo atrás e discutir as formas horizontal x vertical de escalonamento de aplicações. O que são, e qual é a diferença? O escalonamento horizontal, explicado de forma extremamente simples nessa postagem do StackOverflow, consiste em escalonar adicionando mais máquinas ao seu parque de recursos, enquanto o escalonamento “vertical” consiste em escalonar adicionando mais potência a uma máquina existente (e.g., CPU, memória RAM).
No desenvolvimento web, é (quase) sempre preferível o escalonamento horizontal, porque — colocando de uma forma simples — coisas quebram. Servidores travam aleatoriamente. A velocidade das redes degrada sozinha. Eventualmente, centros de dados inteiros ficam offline. Ter mais de um servidor permite planejar saídas para essas quedas, para que sua aplicação continue rodando. Em outras palavras, sua aplicação fica “tolerante a falhas”. Em segundo lugar, o escalonamento horizontal permite a você o mínimo acoplamento de partes diferentes de sua aplicação (servidor web, banco de dados, serviço X, etc.), pois você pode colocá-los para rodar em diferentes servidores. Por fim, você pode atingir um nível em que não é mais possível escalonar verticalmente. Não há computador no mundo grande o suficiente para computar todos os programas de sua aplicação. Pense na plataforma de busca da Google como um exemplo por excelência, mas isso também se aplica a empresas de escala muito menor. A Storyblocks, por exemplo, está sempre rodando de 150 a 400 instâncias do AWS EC2 (um serviço da Amazon que permite rodar seus programas nos servidores da empresa), a qualquer momento. Seria um grande desafio conseguir todo esse poder de computação por escalonamento vertical.
Bem, voltemos para os balanceadores de carga. Eles são o ingrediente secreto que tornam o escalonamento vertical possível. Eles encaminham as requisições que chegam para um de muitos servidores de aplicações (que normalmente são clones / imagens espelhadas uns dos outros) e devolvem a resposta do servidor da aplicação para o cliente. Qualquer um destes deve processar a requisição da mesma forma, portanto, é só uma questão de distribuir as requisições pelo conjunto de servidores de modo a não sobrecarregar nenhum deles.
É isso. Conceitualmente, balanceadores de carga são bastante simples. Por baixo dos panos, certamente há complicações, mas não há necessidade de falar sobre elas em nossa Introdução.
3. Servidor de Aplicação Web
Descrever por alto os servidores de aplicações web é relativamente simples. Eles executam o cerne da lógica do negócio, que é tratar a requisição do usuário e devolver o HTML para o navegador. Para fazer seu trabalho, eles geralmente se comunicam com uma série de componentes de infraestrutura, como bancos de dados, camadas de cache, filas de serviços, serviços de pesquisa, outros microsserviços, filas de dados e de log, dentre outros. Como já falamos acima, você normalmente tem pelo menos dois, e frequentemente muitos mais, plugados em um balanceador de carga para processar as requisições dos usuários.
É relevante saber que implementações de servidores de aplicação exigem que se escolha uma linguagem específica (Node.js, Ruby, PHP, Scala, Java, C# .NET, etc.) e uma arquitetura MVC para web específica para aquela linguagem (Express para Node.js, Ruby on Rails, Play para Scala, Laravel para PHP, etc). Entretanto, aprofundar nos detalhes dessas linguagens e arquiteturas está fora do escopo deste artigo.
4. Servidores de Bancos de Dados
Toda aplicação web moderna lança mão de um ou mais bancos de dados para armazenar informações. Bancos de dados proporcionam formas de definir suas estruturas de dados, inserir novos dados, encontrar dados existentes, atualizar ou apagar dados existentes, computar operações com os dados, entre outros. Na maioria dos casos, os servidores de aplicações web se comunicam diretamente com um banco de dados, assim como os servidores de serviços. Além disso, cada serviço pode ter seu próprio banco de dados isolado do restante da aplicação.
Embora esteja evitando aprofundar muito em tecnologias específicas de cada componente da arquitetura, eu faria um desserviço a vocês se não entrasse no próximo nível de detalhe sobre os bancos de dados: SQL e NoSQL.
SQL significa “Linguagem de Consulta Estruturada” (em inglês, Structured Query Language) e foi inventada nos anos 1970, para proporcionar uma forma padrão de realizar consultas a conjuntos de dados que fosse acessível a um público amplo. Bancos de dados SQL guardam dados em tabelas interconectadas por IDs em comum — geralmente números inteiros. Vamos examinar passo a passo um exemplo simples, de armazenar o histórico de endereços de usuários. Você precisa de duas tabelas — usuarios and enderecos_de_usuario, interligadas pelo ID do usuário. A imagem abaixo contém uma versão bem simples. As tabelas estão interligadas porque a coluna id_usuario na tabela enderecos_de_usuario é uma “chave externa” para a coluna id da tabela usuarios.

Se você não sabe muito sobre SQL, eu recomendo conferir um tutorial passo-a-passo, como esse da Khan Academy. SQL é onipresente na área de desenvolvimento web, por isso você deve conhecer pelo menos o básico, para planejar uma aplicação adequadamente.
NoSQL, que significa “Não-SQL”, é um conjunto de tecnologias de bancos de dados mais recente, que surgiu para lidar com as quantidades massivas de dados que podem ser produzidas por aplicações web em grande porte (a maior parte das variedades de SQL não escalona horizontalmente muito bem, e só consegue escalonar verticalmente até um certo ponto). Se você não sabe nada sobre NoSQL, recomendo começar com uma leitura mais introdutória, como essas:
- https://www.w3resource.com/mongodb/nosql.php
- http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
- https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-nosql
Também é relevante ter em mente que, de mais a mais, a indústria tem adotado o SQL inclusive como uma interface para bancos de dados NoSQL, portanto, você realmente deveria aprender algo de SQL se não souber. É praticamente impossível evitar SQL hoje em dia.
5. Serviço de cache
Um serviço de cache é um simples armazenamento de dados chave/valor que possibilita salvar e recuperar informações em um tempo próximo a O(1) [N. do T.: trata-se de referência à notação matemática Grande-O, ou, em inglês, Big-O, usada em informática para medir o tempo relativo de execução de um código — com certa “liberdade poética” em relação ao uso matemático]. Via de regra, as aplicações mantêm serviços de cache para salvar os resultados de computações demoradas, possibilitando recuperar os resultados do cache, em vez de recomputar tudo da próxima vez que for necessário. Por exemplo, uma aplicação poderia salvar em cache resultados de uma consulta ao banco de dados, de chamadas a serviços externos ou o código HTML de determinada URL, dentre outras tantas utilidades. Seguem alguns exemplos de aplicações reais:
- A Google salva no chace resultados de busca de expressões pesquisadas com frequência, como “cachorro” ou “Taylor Swift”, em vez de recomputar a pesquisa cada vez que ela é feita;
- O Facebook salva em cache boa parte dos dados que você vê quando loga, como dados de postagens, amigos, etc. Para mais detalhes sobrea tecnologia de cache do Facebook, clique aqui.
- A Storyblocks salva em cache a saída HTML de renderizações de React feitas do lado do servidor, resultados de busca, previsões de texto do campo de busca, dentre outros.
As duas tecnologias de servidor de cache mais difundidas são Redis e Memcache. Falarei sobre elas com mais detalhes em outra postagem.
6. Filas e Servidores de Tarefas
A maior parte das aplicações web precisa fazer algum trabalho de forma assíncrona — isto é, nos bastidores, que não está diretamente associado com responder à requisição do usuário. Por exemplo, a Google precisa escarafunchar e indexar toda a internet para conseguir retornar resultados de busca. Ela não faz isso todas as vezes em que você faz uma busca: ao invés disso, ela percorre a web de forma assíncrona, atualizando os índices de buscas no percurso.
Embora existam arquiteturas diferentes para realizar tarefas assíncronas, a mais difundida é o que eu chamo de arquitetura de “fila de tarefas” (em inglês, job queue). Consiste de dois componentes: uma lista de “tarefas” que precisam ser rodadas e um ou mais servidores de tarefas (frequentemente denominados “trabalhadores”, em inglês workers), os quais executam as tarefas na fila.
As filas de tarefas mantêm uma lista de tarefas que precisam ser rodadas de forma assíncrona. A forma mais simples de fila é a “primeira a entrar, primeira a sair” (em inglês, first-in-first-out) — embora a maioria das aplicações termine precisando de algum tipo de sistema de enfileiramento com prioridades. Sempre que a aplicação precisar que uma tarefa seja executada, seja num agendamento regular, seja disparada por ações de usuários, ela simplesmente adiciona a tarefa apropriada à fila.
O Storyblocks, por exemplo, se utiliza de uma fila de tarefas para potencializar boa parte do trabalho que acontece por trás dos panos — e que é necessário para manter nossos serviços. Nós rodamos tarefas para comprimir vídeos e fotos em formatos específicos, processar CSVs [N. do T.: listas de texto em que os valores são separados por vírgulas; a sigla vem do inglês comma-separated values] para aplicar metadados, agregar estatísticas de usuários, enviar e-mails para reset de senha, entre outros. Nós começamos com uma fila FIFO simples, mas avançamos para uma fila com prioridades, para garantir que certas operações mais sensíveis a demora (como enviar e-mails de reset de senha) fossem completadas o mais rápido possível.
Servidores de tarefas processam tarefas. Eles consultam a lista de tarefas para determinar se há trabalho a ser feito e, se houver, eles pegam uma tarefa da lista e a executam. As linguagens e escolhas de arquiteturas por trás são tão diversas quanto para os servidores web, por isso não entrarei em detalhes neste artigo..
7. Full-text Search Service
Many if not most web apps support some sort of search feature where a user provides a text input (often called a “query”) and the app returns the most “relevant” results. The technology powering this functionality is typically referred to as “full-text search”, which leverages an inverted index to quickly look up documents that contain the query keywords.

While it’s possible to do full-text search directly from some databases (e.g., MySQL supports full-text search), it’s typical to run a separate “search service” that computes and stores the inverted index and provides a query interface. The most popular full-text search platform today is Elasticsearch though there are other options such as Sphinx or Apache Solr.
8. Services
Once an app reaches a certain scale, there will likely be certain “services” that are carved out to run as separate applications. They’re not exposed to the external world but the app and other services interact with them. Storyblocks, for example, has several operational and planned services:
- Account service stores user data across all our sites, which allows us to easily offer cross-sell opportunities and create a more unified user experience
- Content service stores metadata for all of our video, audio, and image content. It also provides interfaces for downloading the content and viewing download history.
- Payment service provides an interface for billing customer credit cards.
- HTML → PDF service provides a simple interface that accepts HTML and returns a corresponding PDF document.
9. Data
Today, companies live and die based on how well they harness data. Almost every app these days, once it reaches a certain scale, leverages a data pipeline to ensure that data can be collected, stored, and analyzed. A typical pipeline has three main stages:
- The app sends data, typically events about user interactions, to the data “firehose” which provides a streaming interface to ingest and process the data. Often times the raw data is transformed or augmented and passed to another firehose. AWS Kinesis and Kafka are the two most common technologies for this purpose.
- The raw data as well as the final transformed/augmented data are saved to cloud storage. AWS Kinesis provides a setting called “firehose” that makes saving the raw data to it’s cloud storage (S3) extremely easy to configure.
- The transformed/augmented data is often loaded into a data warehouse for analysis. We use AWS Redshift, as does a large and growing portion of the startup world, though larger companies will often use Oracle or other proprietary warehouse technologies. If the data sets are large enough, a Hadoop-like NoSQL MapReduce technology may be required for analysis.
Another step that’s not pictured in the architecture diagram: loading data from the app and services’ operational databases into the data warehouse. For example at Storyblocks we load our VideoBlocks, AudioBlocks, Storyblocks, account service, and contributor portal databases into Redshift every night. This provides our analysts a holistic dataset by co-locating the core business data alongside our user interaction event data.
10. Cloud storage
“Cloud storage is a simple and scalable way to store, access, and share data over the Internet” according to AWS. You can use it to store and access more or less anything you’d store on a local file system with the benefits of being able to interact with it via a RESTful API over HTTP. Amazon’s S3 offering is by far the most popular cloud storage available today and the one we rely on extensively here at Storyblocks to store our video, photo, and audio assets, our CSS and Javascript, our user event data and much more.
11. CDN
CDN stands for “Content Delivery Network” and the technology provides a way of serving assets such as static HTML, CSS, Javascript, and images over the web much faster than serving them from a single origin server. It works by distributing the content across many “edge” servers around the world so that users end up downloading assets from the “edge” servers instead of the origin server. For instance in the image below, a user in Spain requests a web page from a site with origin servers in NYC, but the static assets for the page are loaded from a CDN “edge” server in England, preventing many slow cross-Atlantic HTTP requests.

Check out this article for a more thorough introduction. In general a web app should always use a CDN to serve CSS, Javascript, images, videos and any other assets. Some apps might also be able to leverage a CDN to serve static HTML pages.
Parting thoughts
And that’s a wrap on Web Architecture 101. I hope you found this useful. I’ll hopefully post a series of 201 articles that provide deep dives into some of these components over the course of the next year or two.